Modernizing Tech Stack at Shippo - Upgrade Python and Django Version

In January 2022, Shippo supported ~50,000 businesses in shipping 1,000s of packages per day. Through our web app and API, we were moving steadily towards our goal of becoming the shipping layer of the internet.
We had grown quickly, building solutions as we conquered challenges in front of us using a tried and tested tech stack. But there was a problem. That tried and tested tech stack had aged and was affecting how we worked and our ability to add more capabilities to our platform. This article tells the story of how we updated our tech stack, the challenges we overcame, and the benefits we've seen, while maintaining a world class service for our customers.
Requirements and Challenges
Even though upgrading our software was important for our future, we needed to ensure we could continue to serve our existing customers and also make progress on adding additional capabilities that were needed to grow our business during these upgrades. This created rules we needed to work within.
- All changes were backwards compatible
- Customers would not be required to make changes
- Shippo engineers could still ship new features
- Changes could quickly be rolled back
- Large customers must be protected from any potential issues
Some of the challenges included:
- Managing a large code base (over 1.1 millions lines of code) with active contributions from dozens of teams
- Legacy code with the oldest commit / code written in 2013 and a lot of the code not updated in many years
- Several packages / libraries required updating
- Implementing changes without disrupting customers initiating millions of requests each day.
Phases and Timelines
We divided the project into 4 phases. Each phase had its own set of operations, requirements, and challenges. Here, we represent a timeline view of each of the phases and describe below what each phase meant.

Phase 1 - Automated Migrations, Performance benchmarks and Unit Tests
We set up a separate py3 repository and started to commit the newly generated code created from the automated scripts that were used. Other engineers continued to push code in the original py2 repo which was deployed to our QA and production serving live traffic.
Even though there are several libraries that are available to help with migrating Python 2 to Python 3 we used 2to3 and six to apply some of the code changes.
Technical Challenges / Fixes
Python version upgrade (2.7 to 3.9) - Although easy enough to handle, there were some challenges with the Python version upgrade. Here are some of them:
- The difference in Python’s handling of unicode strings. This was by far the most widespread issue with far-reaching consequences.
- Changes related to integer division.
- Iterable objects replacing lists as return values.
- A particularly stubborn problem was converting all occurrences of methods, attributes, variables called ‘async’, a reserved word in Py3, to something else without affecting use of the word in public facing API contracts.
Python libraries upgrades - The most challenging problems in this category were related to the Django upgrade and its related libraries.
- Django upgrade (1.6 to 3.x) changes involved many well documented changes in API.
- The DRF upgrade (2.3 to 3.x) was a challenging undertaking as it included the breaking changes introduced in DRF 3.0. We overcame these with a combination of refactoring of the codebase and a considerable modification of DRF’s internals.
- Libraries/infrastructure incompatibilities - This migration was accompanied by a considerable overhaul of the underlying infrastructure. Sometimes this resulted in incompatibilities between the new versions of libraries and infrastructure or between different libraries themselves. Here are some examples:
- At one point, the new Django version was working with the old version of the Postgres instance (10.x). In an obscure corner case, the new Django’s ORM emits a query that is not allowed in Postgres 10.x, which in our case resulted in consistent errors in one of the most important parts of the codebase: label generation. We solved the problem by temporarily monkey patching Django’s ORM to not emit the offending query, and, finally, upgrading to Postgres 14.x, which is compatible with the new Django version.
- The problem was permanently solved when we upgraded to celery (5.x), which included a fix.
- The new version of memcached client pylibmc produced intermittent cache misses in production. The problem disappeared after the switch to pymemcache.
Phase 2 - Integration Environment and Integration Tests
We set up a separate environment (staging) to allow us to deploy the Python 3 code in an integration environment which had other services also running so that we could check how the new code worked with the system. This is where we ran our integration tests that allowed us to uncover any potential issues with some of our integrations with other internal and external services.
This was also the time when all the teams across the company started additional testing for their respective areas.
Phase 3 - Functional Tests and Bug Fixes
We utilized our quality engineering team to help with more detailed testing for the code changes. With their experience, they identified a lot of the issues that we could fix before going live. Based on the quality team’s assessment, we triaged our issues by severity, the most critical issues labeled as Sev1. This method helped us to correctly assign our resources to issues that would affect our customers.
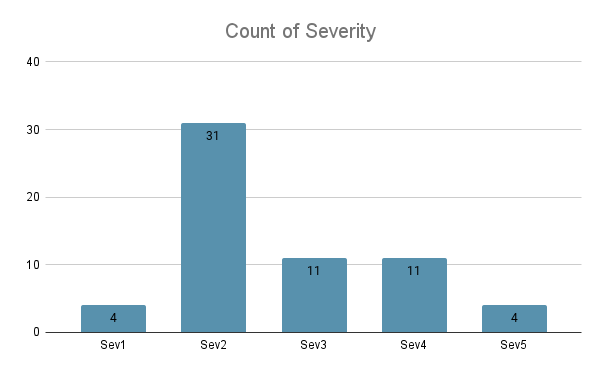
A lot of key issues related to our customer’s critical workflows were identified and fixed during this time period. We also spent time on testing areas that did not have automated test coverage. For example, our internal admin pages, which our support teams rely heavily on. This allowed us to continue to enable other internal teams to support our customers.
Phase 4 - Production Rollouts
We have three different sets of customers that use our product: Web app, Public API and Platform API customers. Even though the technology and majority of the code is the same for most of the customers, there are specific use cases that each of the customer bases have that exercise different parts of our code base.
.png)
There were different ideas about how we wanted to distribute / cutover traffic between py2 and py3 workers. In the end, we settled on using the traffic routing feature from Istio to enable the traffic splitting capability. This approach is similar to Canary deployment, where a small percentage of traffic is served by the new py3 workers. Once we built up the confidence and fixed any obvious error, we could slowly increase the traffic to eventually letting py3 workers take over all requests.
Advantages to this approach:
- Reuse the existing network infrastructure, e.g., same DNS and the same ingress gateways. This has the least impact on customers as they can continue sending requests to the same endpoint without knowing the underlying change.
- All workers (py2 and py3) are running in parallel. This allows us to rollback or roll forward at a moment of notice.
- Change is simple. The only thing that is changing is the Istio routing decision.
Disadvantages:
- More resource is required to support more services running in parallel
- Routing status can be potentially confusing as not everyone is following the latest update.

The initial design idea is simple. Imagine that there are multiple dials on a dashboard. Each dial represents one type of traffic, e.g. dial one for everything that goes through /path_one, and dial two for /path_two, and so on. Although it would have been useful to have a dial for each of the endpoints, we decided to add this capability for the top traffic end points. The implementation is simple.
As we progressed further in the project, we realized that the project needed to support multiple streams of development efforts, and a simple routing decision was not able to cover more complex use cases. For example, how could a developer test a new change for a bug in py3. Or how could we test a new feature and confirm that it works the same between py2 and py3. And all of this was happening when routing decisions were being updated regularly for reasons beyond their control. We needed a mechanism that does not require changing traffic split back and forth, while allowing anyone the ability to always hit the same endpoint with the confidence in knowing that their traffic is being served by their preferred choice, py2 or py3 backend service.
This is when we introduced inclusion and exclusion lists. The inclusion list allows anyone to always hit the py3 backend worker, while the exclusion list is the opposite. This is achieved with a simple request header. The requester specifies a predefined header value, and Istio routes the specific call to the appropriate backend service. This new approach also allowed our partners to have sneak previews ahead of the full rollout.
The implementation is updating the “match” block of the traffic rule in the Istio virtual service. Notice the routing decision for the rule is hardcoded to designated backend service in this case
(see below)
Observability throughout
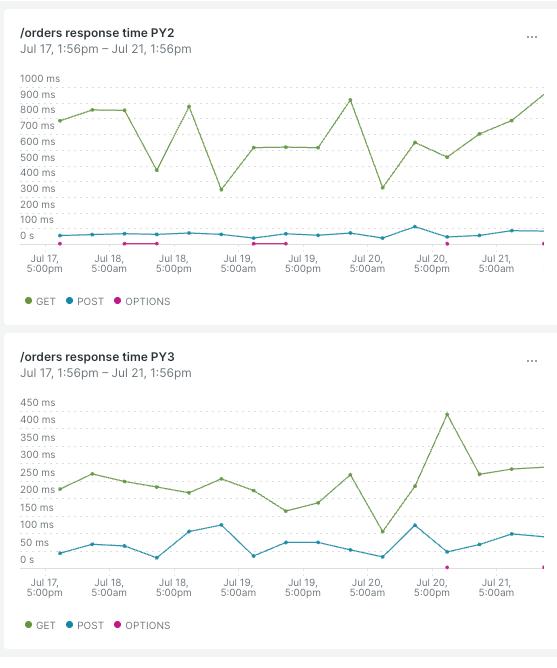
During the production roll outs for each of our customer base, we built dashboards, traffic and request / response monitoring to enable us to detect any issues that customers may encounter:
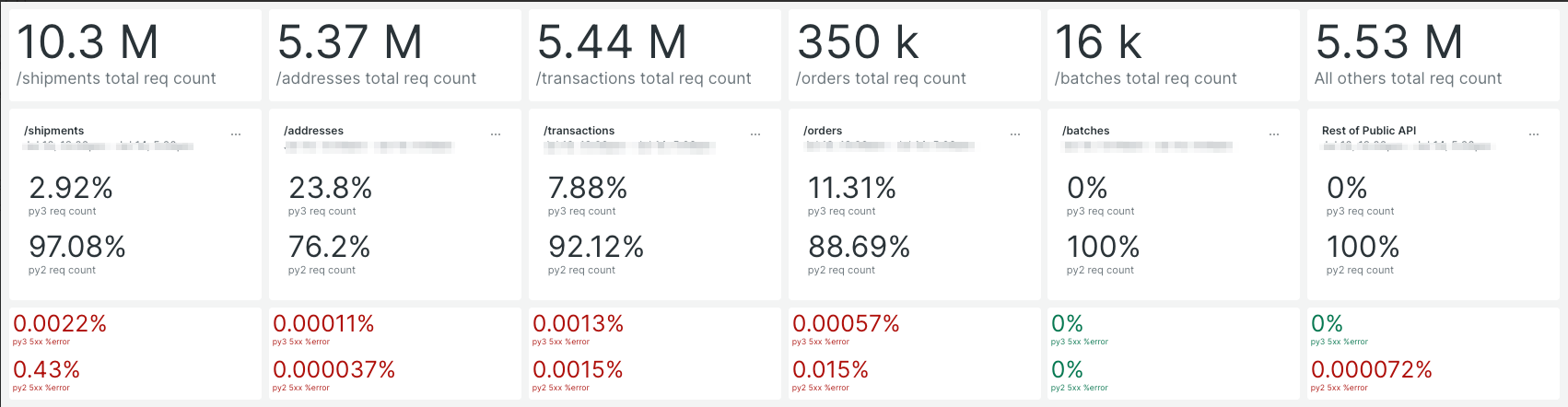

This allowed us to compare and make sure that we were getting better in terms of our responses or if there were differences in errors, we were able to identify any systematic issues quickly. If needed, we could roll back the percentage roll out that we just did or fix the issues that we noticed from our monitors.
Communications
Since this was a large change and could have had an impact on customers, and affected our other deliverables, we provided regular updates to internal stakeholders regarding the progress and the roll outs. This helped customer support and partner managers proactively inform customers and also be able to quickly escalate unexpected behaviors being observed after a roll out or dial up as described above.
Because there were multiple dials across different customer bases and services, we built out easy to consume visuals for everyone in the company to understand and know the state of things. Here is a snapshot from one of the weekly updates:
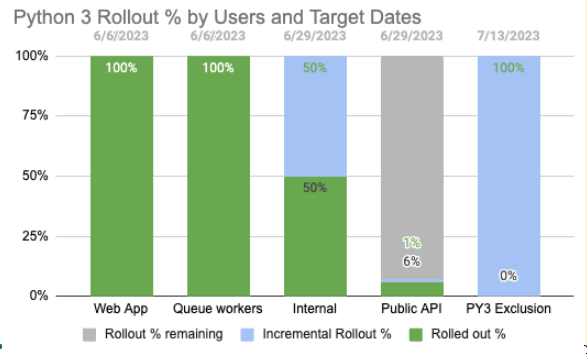
Wins and Future
We updated the Django version from 1.22 to 3.2 and Python 2.7 to 3.2. Even though we are moving to a service oriented architecture, our Python / Django monolith has a lot of code that serves a lot of customers.
Performance Gains
The recent upgrades have allowed us to modernize our technology stack, get performance gains and have helped us build better observability. We are seeing noticeable performance gains averaging ~20% across the board.
Security fixes
Through the process of the upgrade and some additional focus on fixing security vulnerabilities, we were able to fix over 600 security vulnerabilities.
Even though there were several challenges during the entire process, we continually learned from each challenge, established better processes, tooling, testing, and observability in place to evolve our release processes. The roll outs helped us get a deeper understanding of how different customers are using our products differently. The upgrade also enabled us to use modern observability tools. Most importantly, the upgrade allows engineers to use newer libraries to build new features.
We look forward to serving our customers with modern, high quality and reliability software. Even though there were several engineers involved in the project, special shout out to Bojan Gornik, Eric Leu and Pragya Jaiswal for all the perseverance and creative problem solving.
Looking for a multi-carrier shipping platform?
With Shippo, shipping is as easy as it should be.
- Pre-built integrations into shopping carts like Magento, Shopify, Amazon, eBay, and others.
- Support for dozens of carriers including USPS, FedEx, UPS, and DHL.
- Speed through your shipping with automations, bulk label purchase, and more.
- Shipping Insurance: Insure your packages at an affordable cost.
- Shipping API for building your own shipping solution.
Stay in touch with the latest insights
Be the first to get the latest product releases, expert tips, and industry news to help you save time and money on shipping.
Loading...
Thanks for your submission!